



- LEARNING OBJECTIVE
In this blog, we’ll go through some of the most common data structures and algorithms that can be used to Bachelorarbeit schreiben lassen kosten develop efficient programmes. We’ll also go through several techniques to algorithm design and different notations for evaluating algorithm performance.
1.FUNDAMENTAL TERMINOLOGY
In the previous blog, we learned the fundamentals of Python programming and learned how to write, debug, and run simple Python programmes.
Our goal has been to create good programmes, where a good programme is defined as one that does following:
- runs correctly
- is simple to read and comprehend,
- is simple to debug
- is simple to change.
A programme should, without a doubt, produce accurate results, but it should also execute quickly. When a programme runs in the shortest amount of time and uses the least amount of memory, it is considered to be efficient. Certain data management ideas must be applied in order to develop efficient applications.
The concept of data management is a complex task that includes activities like data collection, organization of data into appropriate structures, and developing and maintaining routines for quality assurance. Data structure is a crucial part of data management and a data structure is basically a group of data elements that are put together under one name, and which defines a particular way of storing and organizing data in a computer so that it can be used efficiently.
2.Where does DSA used?
Data structures are used in almost every program or software system. Some common examples of data structures are arrays, linked lists, queues, stacks, binary trees, and hash tables. Data structures are widely applied in the following areas:
-
Compiler design
-
Operating system
-
Statistical analysis package
-
DBMS
-
Numerical analysis
-
Simulation
-
Artificial intelligence
-
Graphics
3.Elementary Data Structure Organization
A program’s building blocks are data structures. It’s possible that a software written using erroneous data structures will not perform as planned. As a result, it is necessary for a programmer to select the most appropriate data structures for a programme. A value or set of values is referred to as data. It specifies the value of a variable or a constant (for example, student grades, employee names, customer addresses, and the value of a variable).A data item that has no subordinate data items is referred to as an elementary item, whereas a data item that has one or more subordinate data items is referred to as a group item. A student’s name, for example, could be broken down into three sub-items—first name, middle name, and last name—but his roll number is usually handled as a single item. A record is a grouping of data elements.
For example, the name, address, course, and marks obtained are individual data items. But all these data items can be grouped together to form a record. A file is a collection of related records. For example, if there are 60 students in a class, then there are 60 records of the students. All these related records are stored in a file. Similarly, we can have a file of all the employees working in an organization, a file of all the customers of a company, a file of all the suppliers, so on and so forth. Moreover, each record in a file may consist of multiple data items but the value of a certain data item uniquely identifies the record in the file. Such a data item K is called a primary key, and the values K1 , K2 … in such field are called keys or key values. For example, in a student’s record that contains roll number, name, address, course, and marks obtained, the field roll number is a primary key. Rest of the fields (name, address, course, and marks) cannot serve as primary keys, since two or more students may have the same name, or may have the same address (as they might be staying at the same place), or may be enrolled in the same course, or have obtained same marks.


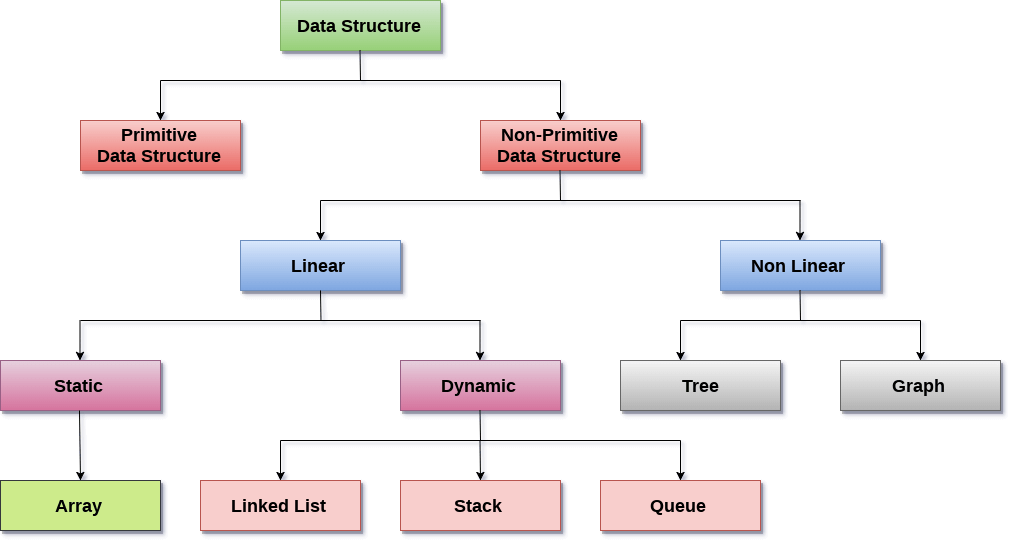
Linear Data Structures:
- If all of the elements of a data structure are ordered in a linear order, it is called linear. The elements of linear data structures are stored in a non-hierarchical manner, with each element having successors and predecessors except the first and last.
Types of Linear Data Structures are given below:
Arrays:
- An array is a collection of similar type of data items and each data item is called an element of the array. The data type of the element may be any valid data type like char, int, float or double.
- The elements of array share the same variable name but each one carries a different index number known as subscript. The array can be one dimensional, two dimensional or multidimensional.
- The individual elements of the array age are: age[0], age[1], age[2], age[3],……… age[98], age[99].
Linked List:
- Linked list is a linear data structure which is used to maintain a list in the memory. It can be seen as the collection of nodes stored at non-contiguous memory locations. Each node of the list contains a pointer to its adjacent node.
Stack:
- Stack is a linear list in which insertion and deletions are allowed only at one end, called top.
- A stack is an abstract data type (ADT), can be implemented in most of the programming languages. It is named as stack because it behaves like a real-world stack, for example: – piles of plates or deck of cards etc.
Queue:
- Queue is a linear list in which elements can be inserted only at one end called rear and deleted only at the other end called front.
- It is an abstract data structure, similar to stack. Queue is opened at both end therefore it follows First-In-First-Out (FIFO) methodology for storing the data items.
Non Linear Data Structures:
- This data structure does not form a sequence i.e. each item or element is connected with two or more other items in a non-linear arrangement. The data elements are not arranged in sequential structure.
Types of Non Linear Data Structures are given below:
Trees:
- Trees are multilevel data structures with a hierarchical relationship among its elements known as nodes. The bottommost nodes in the herierchy are called leaf node while the topmost node is called root node. Each node contains pointers to point adjacent nodes.
- The parent-child relationship between the nodes is the basis of the tree data structure. Except for the leaf nodes, each node in the tree can have several children, although each node can only have one parent, with the exception of the root node. There are numerous classifications for trees, which will be addressed later in this course.
Graph:
- Graphs are the graphical representation of a collection of items (represented by vertices) linked by edges. A graph differs from a tree in that it can have a cycle, whereas trees cannot.





